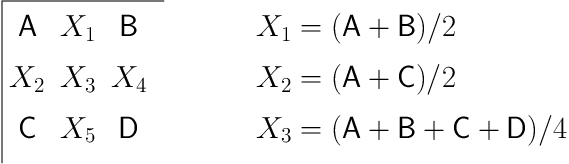Video Coding Fundamentals
Juan Francisco Rodríguez Herrera
Vicente González Ruiz
July 10, 2017
Contents
1 Sources of redundancy
- Spatial redundancy: Pixels are very similar in its neighborhood or tends
to repeat textures.
- Temporal redundancy: Temporally adjacent images are typically very
alike.
- Visual redundancy: Humans hardly perceive high spatial and temporal
frequencies (we like more low frequencies).
2 Memory requirements of PCM video
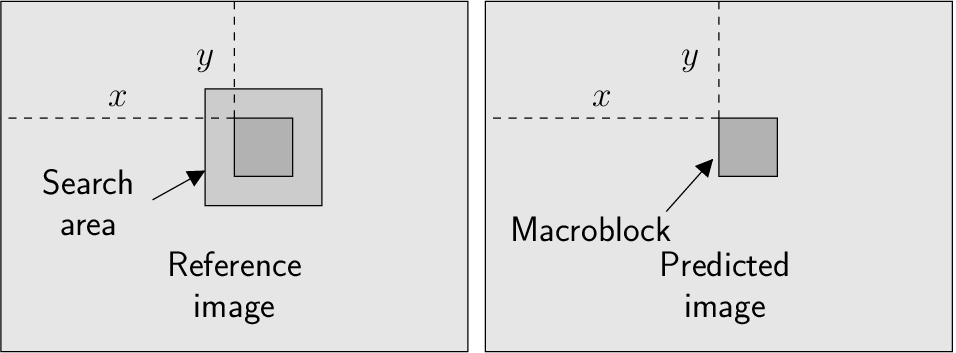
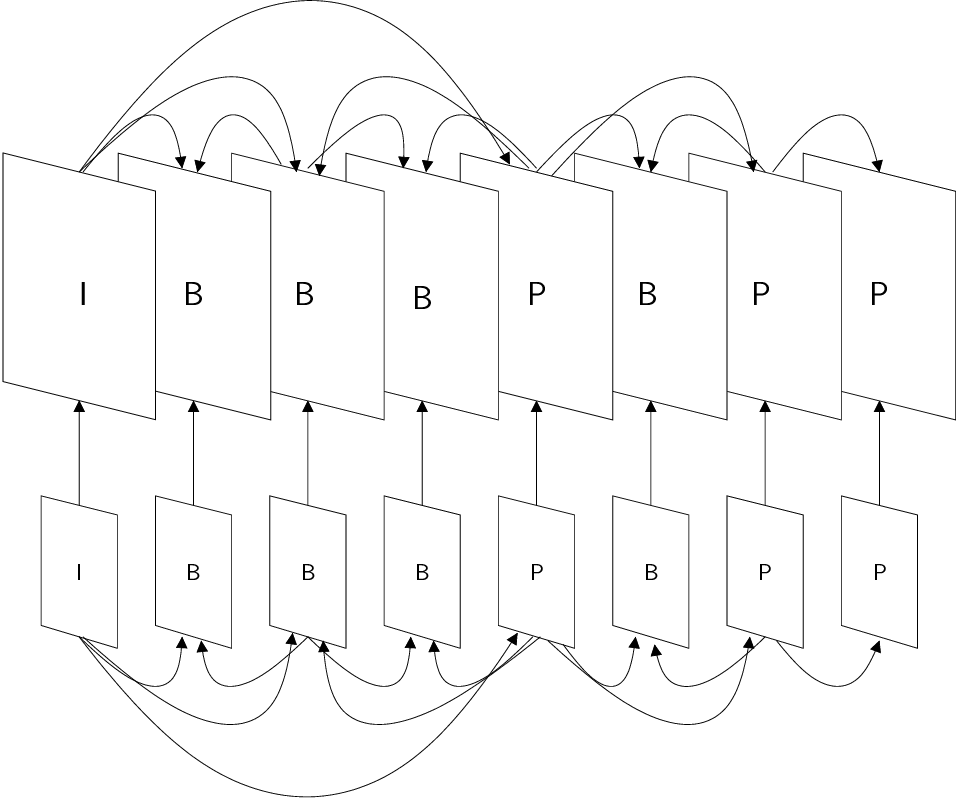
3 Block-based ME (Motion Estimation)
- Usually, only performed by the encoder.
- ME removes temporal redundancy. A predicted image can be encoded as
the difference between it and another image called prediction image which
is a motion compensated projection of one or more images named reference
images. ME tries to generate residue images as close as possible to the
null images.
- Usually, the reference image/s is/are divided in blocks of
pixels called macroblocks.
- Each reference block is searched in the predicted image and the best match
is indicated by mean of a motion vector.
- Depending on the success of the search and the number of reference images, the
macroblocks are classified into:
- I: When the compression of residue block generates more bits than
the original (predicted) one.
- P: When it is better to compress the residue block and there is only
one reference macroblock.
- B: The same, but if we have two reference macroblocks.
- S (skipped): When the energy of the residue block is smaller than
a given threshold.
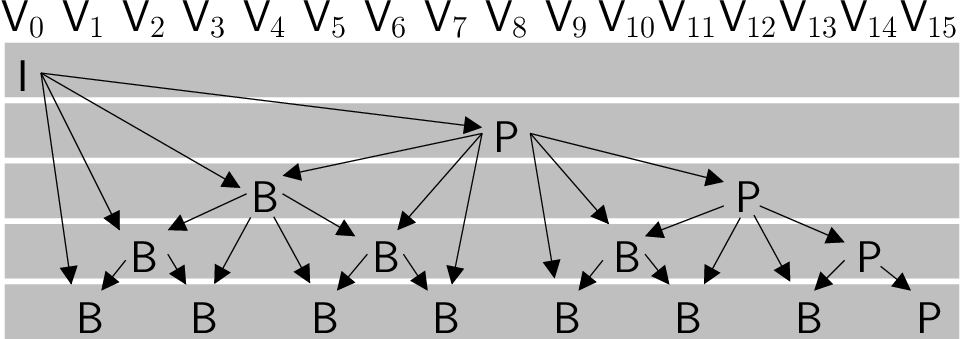
- I-pictures are composed of I macroblocks, only.
- P-pictures do not have B macrobocks.
- B-pictures can have any type of macroblocks.

4 Sub-pixel accuracy
- The motion estimation can be carried out using integer pixel accuracy or
a fractional (sub-) pixel accuracy.
- For example, in MPEG-1, the motion estimation can have up to 1/2 pixel
accuracy. A bi-linear interpolator is used:
5 Matching criteria (similitude between macroblocks)
- Let
and
the macroblocks which we want to compare. Two main distortion metrics are
commonly used:
- Mean Square Error:
- Mean Absolute Error:
- These similitude measures are used only by the compressor. Therefore, any
other one with similar effects (such as the error variance or the error entropy)
could be used also.
6 Searching strategies
- Only performed by the compressor.
- Full search: All the possibilities are checked. Advantage: the best
compression. Disadvantage: CPU killer.
- Logaritmic search: It is a version of the full search algorithm where the
macro-blocks and the search area are sub-sampled. After finding the best
coincidence, the resolution of the macro-block is increased in a
power of 2 and the previous match is refined in a search area of
,
until the maximal resolution (even using subpixel accuracy) is
reached.
- Telescopic search: Any of the previously described techniques can be
speeded up if the searching area is reduced. This can be done supposing
that the motion vector of the same macro-block in two consecutive images
is similar.
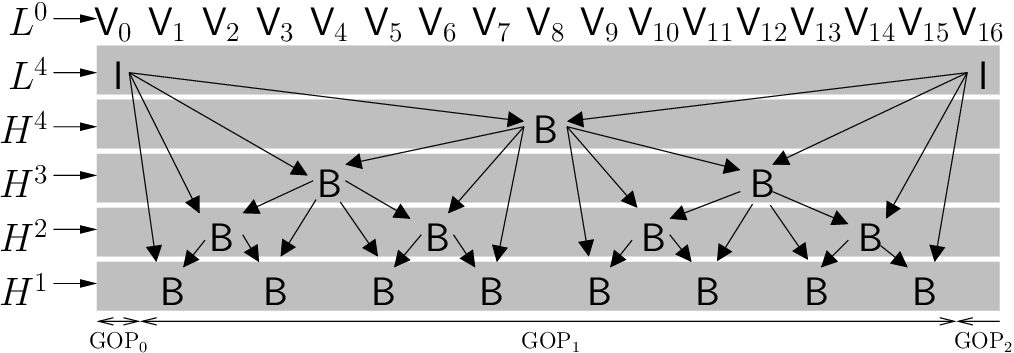
7 The GOP (Group Of Pictures) concept
- The temporal redundancy is exploited by blocks of images called GOPs.
This means that a GOP can be decoded independently of the rest of GOPs.
Here an example:
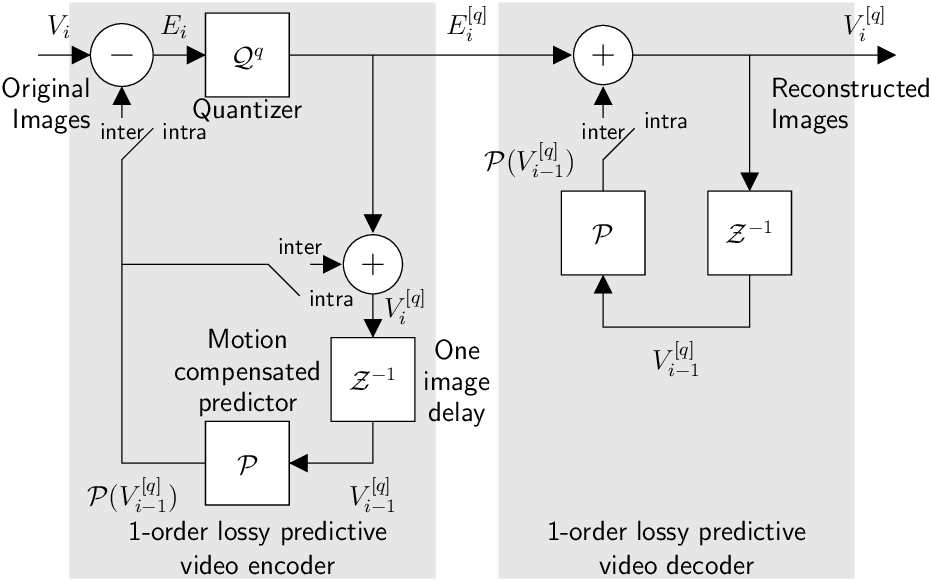
8 Lossy predictive video coding
Let the i-th image of
the video sequence and
and approximation of
with quality
(most video compressors are lossy). In this context, an hybrid video codec
(t+2d)
has the following structure:
9 MCTF (Motion Compensated Temporal Filtering)
- This is a DWT where the input samples are the original video images and
the output is a sequence of residue images.
10 t+2d vs. 2d+t vs. 2d+t+2d
- t+2d: The sequence of images is decorrelated first along the time (t) and
the residue images are compressed, exploiting the remaining spatial (2d)
redundancy. Examples: MPEG* and H.26* codecs (except H.264/SVC).
- 2d+t: The spatial (2d) redudancy is explited first (using typically the
DWT) and next the coefficients are decorrelated along the time (t). To
date this has only been experimental setup because most transformed
domains are not invariant to the displacement.
- 2d+t+2d: The fist step creates a Laplacian Pyramid (2d), which
is invariant to the displacement. Next, each level of the pyramid
is decorrelated along the time (t) and finally, the remaining spatial
redundancy is removed (2d). Example: H.264/SVC.
11 Deblocking filtering
- Block based video encoders (those than use block-based temporal
decorrelation) improve their performance if a deblocking filter in used to
create the quantized prediction predictions.
- The low-pass filter is applied only on the block boundaries.
12 Bit-rate allocation
- Under a constant quantization level (constant video quality), the number
of bits that each compressed image needs depends on the image content.
Example:
- The encoder must decide how much information will be stored in each
residue image, taking into account that this image can serve as a reference
for other images.
13 Quality scalability
- Ideal for remote visualization environments.
- In reversible codecs, .
14 Temporal scalability
|
| (1) |
where is the number
of pixtures in
and
denotes the Temporal Resolution Level (TRL).
- Notice that .
- Useful for fast random access.
15 Spatial scalability
- Useful in low-resolution devices.
- In reversible codecs,
and
has a
resolution, where
is the resolution of .