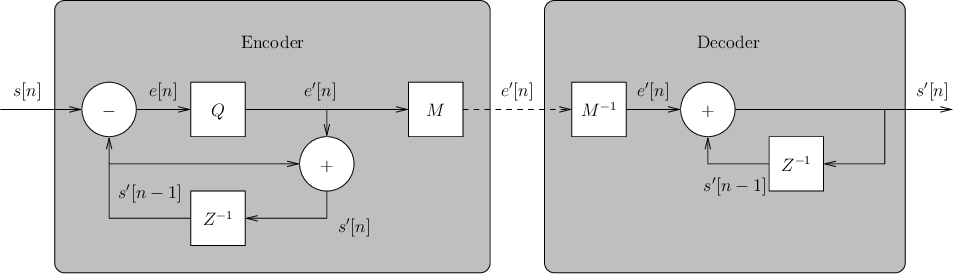
Debido a su naturaleza continua, una señal de audio digital en formato PCM tiende a general pulsos vecinos de valor parecido. Esto puede utilizarse para reducir el rango dinámico de la señal, representando la muestra en función de la anterior . En otras palabras, en lugar de codificar , es posible codificar el error de predicción
| (1) |
Es evidente que esta codificación predictiva es revesible (podemos determinar a partir de ). Sin embargo, en aras de aumentar el nivel de compresión, el error de predicción se cuantifica. Esta acción complica ligeramente el codificador porque en él es necesario usar para las predicciones las mismas muestras que el descodificador va a generar, o de lo contrario, se producía una diferencia incremental entre las predicciones generadas en el compresor y el descompresor (drift error). Gráficamente:
Nótese que las muestras reconstruidas son igual a
| (2) |
y
| (3) |
El módulo representa un modulador digital (PCM, por ejemplo) que para esta práctica debería usar un código de longitud fija de 8 bits para representar los errores de predicción cuantificados . Por tanto, diséñese el correspondiente quantificador que posea 256 niveles de representación. Más información en http://web.stanford.edu/class/ee368b/Handouts/15-DPCM.pdf y en http://en.wikipedia.org/wiki/Quantization_%28signal_processing%29.
Usense las entradas y salidas standard para que la modulación/desmodulación pueda aplicarse en tiempo real. Compuebe que el codificador funciona con:
donde DPCM -c ejecuta el codificador y DPCM -d el descodificador. La nota para este trabajo será proporcional a la relación señal/ruido conseguida. Más información en http://en.wikipedia.org/wiki/Signal-to-noise_ratio y en http://www.ual.es/~vruiz/Software/snr.tar.gz.
Finalmente, en Python es posible leer y escribir la salida estándar usando: