
-- Ingeniería de Computadores --
Analizar las prestaciones del sistema de memoria de un computador mediante el diseño e implementación de benchmarks sencillos.DESCRIPCIÓN:
En esta práctica se diseñarán benchmarks que permitan medir las prestaciones de un sistema de memoria. Se analizará cómo el rendimiento depende fuertemente del empleo de la memoria cache y del ``stride'' de acceso a memoria.
Se diseñarán dos benchmarks, mem1d y mem2d, que realizarán un gran número de operaciones enteras sobre estructuras de datos unidimensionales y bidimensionales, respectivamente. Los benchmarks permitirán el análisis de los efectos del stride en el acceso a la memoria.
El rendimiento se medirá en términos de MOPS (millones de operaciones por segundo), una medida relativa de cuántas operaciones enteras sencillas se pueden efectuar por segundo cuando se accede a la estructura de datos según diversas formas.
DESARROLLO DE LA PRÁCTICA
El benchmark mem1d ha de medir el tiempo requerido para efectuar un gran número de sumas enteras de 32 bits sobre un array unidimensional. El benchmark tiene que realizar un conjunto de tests con diferente tamaño del problema. En algunos tests el tamaño empleado será tal que todos los datos se podrán localizar en la cache, mientras que en otros tests el tamaño del problema será tan grande que se requerirá otro nivel de cache o la memoria principal. Consecuentemente, se podrá apreciar cómo varía el ancho de banda de acceso a memoria, e incluso se podrá deducir el tamaño de la cache a partir de los resultados obtenidos.
Implementa en lenguaje C el benchmark mem1d según el siguiente
algoritmo:
Los resultados que ha de proporcionar el benchmark para cada iteración son:
| Tamaño del problema: | loop_size * sizeof(int) bytes | |
| Wall-time: | Tiempo real que se tardó. | |
| User-time: | Tiempo de CPU de usuario. | |
| Sys-time: | Tiempo de CPU de sistema. | |
| CPU-time: | Tiempo de CPU total (usuario + sistema). | |
| CPU/Wall: | Relación CPU-time frente Wall-time: da una idea de la carga que | |
| tenía el sistema cuando se ejecutó el código. | ||
| MOPS : | Millones de operaciones por segundo, medido en base al Wall-time. |
Compila el benchmark con el gcc, sin emplear flags de optimización:
gcc -o mem1d mem1d.c
3.- Ejecución del benchmark mem1d y análisis de los resultados.
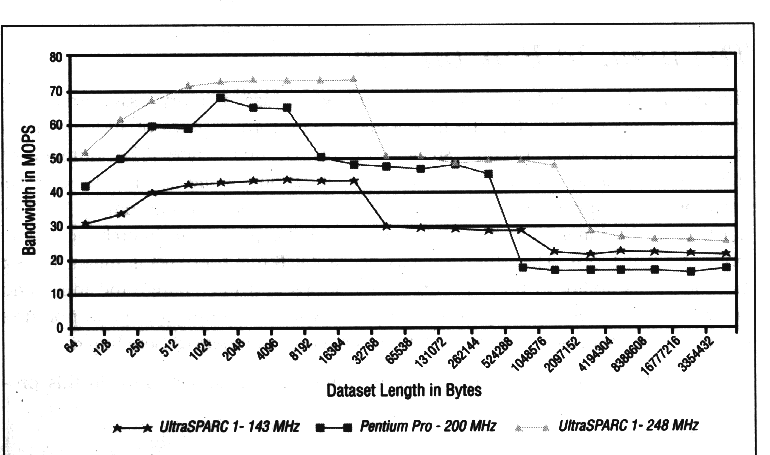
En este punto sería muy interesante que analizaras y compararas los MHz de los procesadores de estos computadores con los MOPS obtenidos ... Con este tipo de benchmarks se suelen presentar situaciones en las que se comprueba que procesadores con mayor frecuencia de reloj (MHz) presentan el mismo rendimiento que otros con menos MHz porque disponen de la misma o peor SRAM/DRAM.
Por ejemplo, en la gráfica anterior se puede comprobar que para
tamaños de problema que no superen los 512KB el Pentium Pro a 200
MHz se comporta mejor que el UltraSPARC 1 a 143 MHz. Sin embargo, para
un tamaño del problema mayor de 512KB, el rendimiento del Pentium
Pro cae incluso por debajo de las prestaciones de ese UltraSPARC.
Compila el benchmark de nuevo, esta vez habilitando el flag de optimización -O2:
gcc -O2 -o mem1d_opt mem1d.c
y repite el paso 3 con este nuevo programa. ¿Han mejorado los resultados sustancialmente?, ¿cuál crees que puede ser la razón?:
El benchmark mem2d ha de medir el tiempo requerido para efectuar un gran número de sumas enteras de 32 bits sobre un array bidimensional. Las operaciones se efectuarán siguiendo dos órdenes de recorrido distintos: En primer lugar se recorrerá el array siguiendo un orden por filas, lo cual se traduce en un acceso non-unit stride. Después se efectuarán las operaciones siguiendo un recorrido por columnas, lo cual equivale a un acceso de stride unidad. En los dos recorridos, el número de filas del array permanecerá constante, mientras que el número de columnas se va incrementando con las iteraciones. Los resultados permitirán analizar, en términos de MOPS, el ancho de banda de memoria con accesos con stride unidad y no-unidad.
Implementa en lenguaje C el benchmark mem2d según el siguiente
algoritmo:

Los resultados que se tienen que presentar son los mismos que en el caso del benchmark mem1d.
2.- Compilación.
Compila el benchmark con el gcc, sin emplear flags de optimización.
gcc -o mem2d mem2d.c
3. Ejecución y análisis de los resultados.
Al igual que se realizó con el mem1d, ejecuta el benchmark mem2d en varios computadores y compara los resultados. El principal efecto que se ha de observar es que el acceso unit-stride proporciona un número mayor de MOPS, que se incrementa conforme aumenta el tamaño del problema, mientras que el acceso non-unit stride proporciona un número bastante bajo de MOPS, que se decrementan con el tamaño del problema. Al igual que se realizó con el mem1d, crea una gráfica MOPS-tamaño del problema que muestre el conjunto de los resultados.
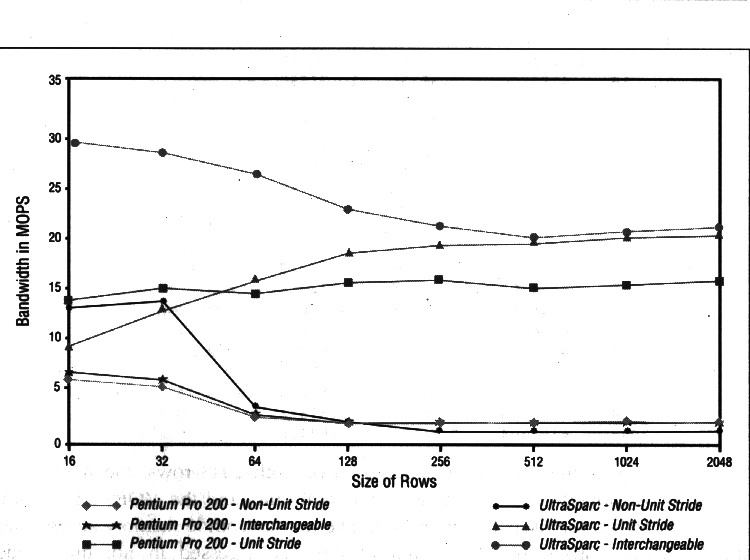
A modo de ejemplo se muestra una gráfica que compara el rendimiento
obtenido con un Pentium Pro y un UltraSPARC para diversos accesos a memoria
(con stride unidad y no-unidad,
ignórese las curvas etiquetadas con Interchangeable).
Se puede comprobar cómo el acceso por stride unidad proporciona
un rendimiento bastante superior al alcanzado en los accesos non-unit stride,
en los cuales el efecto del cache thrashing es devastador.
4.- Nueva compilación y ejecución del benchmark mem2d.
Compila el benchmark de nuevo, habilitando el flag de optimización -O2:
gcc -O2 -o mem2d_opt mem2d.c
y repite el paso 3 con este nuevo programa. ¿Han mejorado los resultados sustancialmente?, ¿cuál crees que puede ser la razón?: